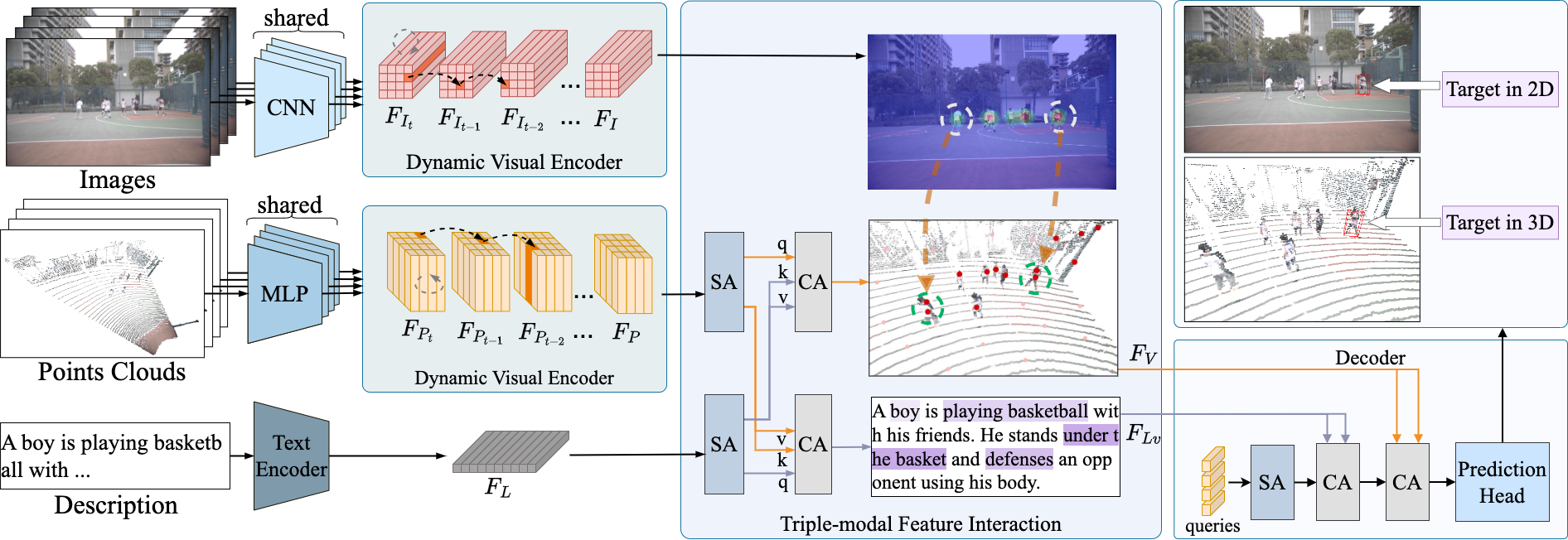
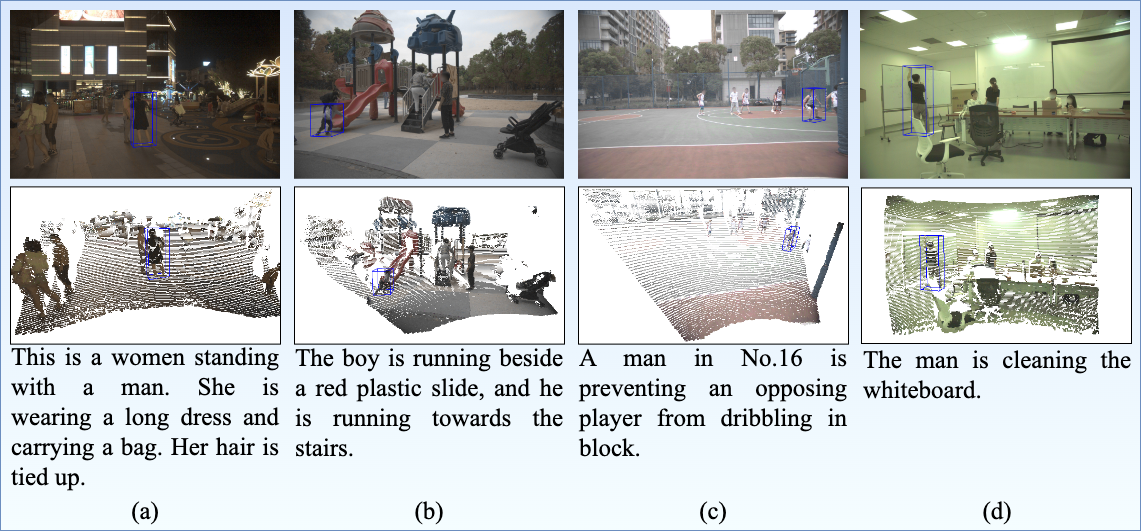
We introduce the task of 3D visual grounding in large-scale dynamic scenes based on natural linguistic descriptions and online captured multi-modal visual data, including 2D images and 3D LiDAR point clouds. We present a novel method, dubbed WildRefer, for this task by fully utilizing the rich appearance information in images, the position and geometric clues in point cloud as well as the semantic knowledge of language descriptions. Besides, we propose two novel datasets, i.e., STRefer and LifeRefer, which focus on large-scale human-centric daily-life scenarios accompanied with abundant 3D object and natural language annotations. Our datasets are significant for the research of 3D visual grounding in the wild and has huge potential to boost the development of autonomous driving and service robots. Extensive experiments and ablation studies demonstrate that our method achieves state-of-the-art performance on the proposed benchmarks.
 Introduction to the 3DVGW task and related application. The assistive robot observes the dynamic scene and locates the 3D object in the physical world according to natural language descriptions. Then, the robot moves to the target object to provide service. WildRefer provides a LiDAR-camera multi-sensor-based solution, which can conduct 3D visual grounding in large-scale unconstrained environment.
Introduction to the 3DVGW task and related application. The assistive robot observes the dynamic scene and locates the 3D object in the physical world according to natural language descriptions. Then, the robot moves to the target object to provide service. WildRefer provides a LiDAR-camera multi-sensor-based solution, which can conduct 3D visual grounding in large-scale unconstrained environment.