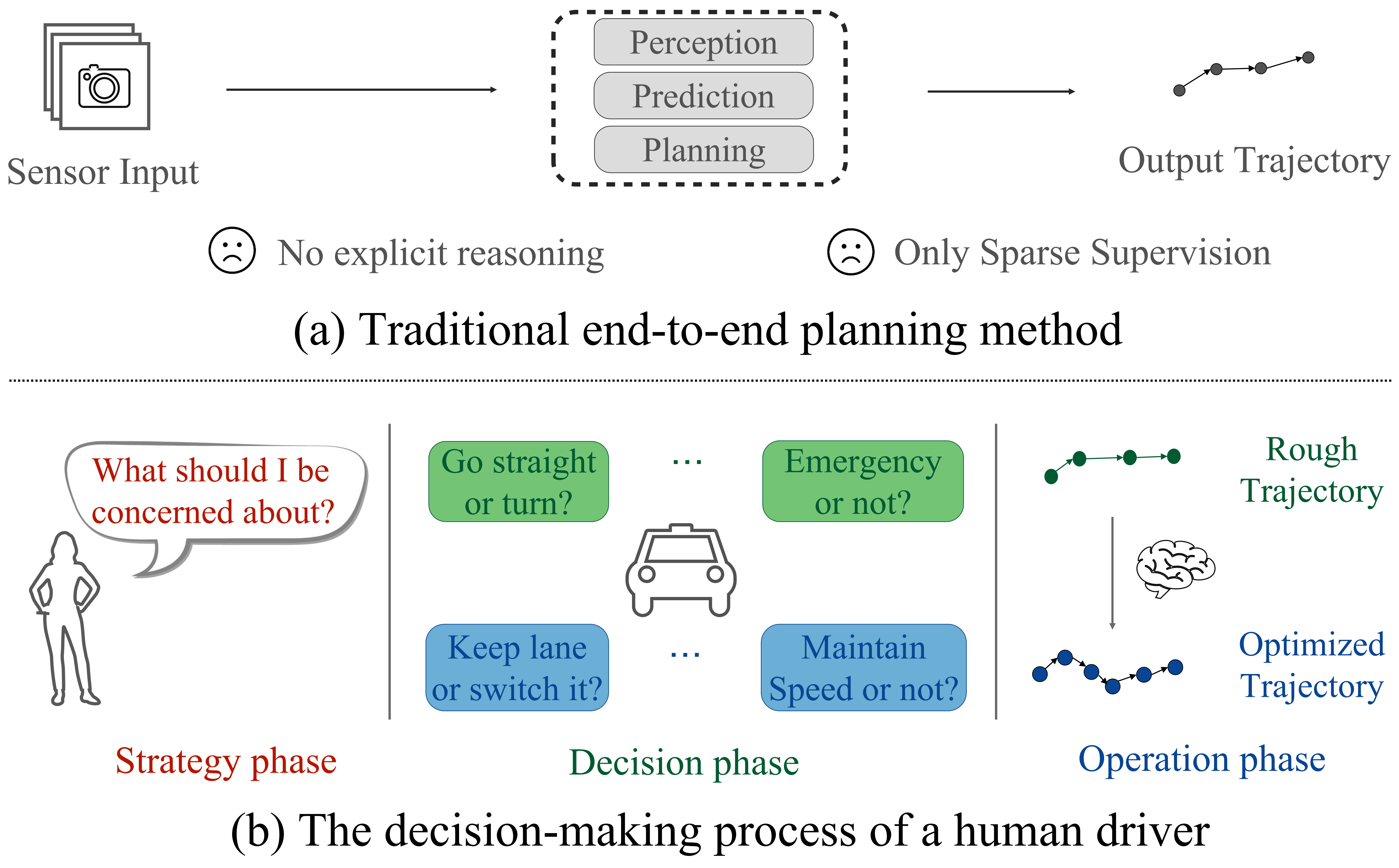
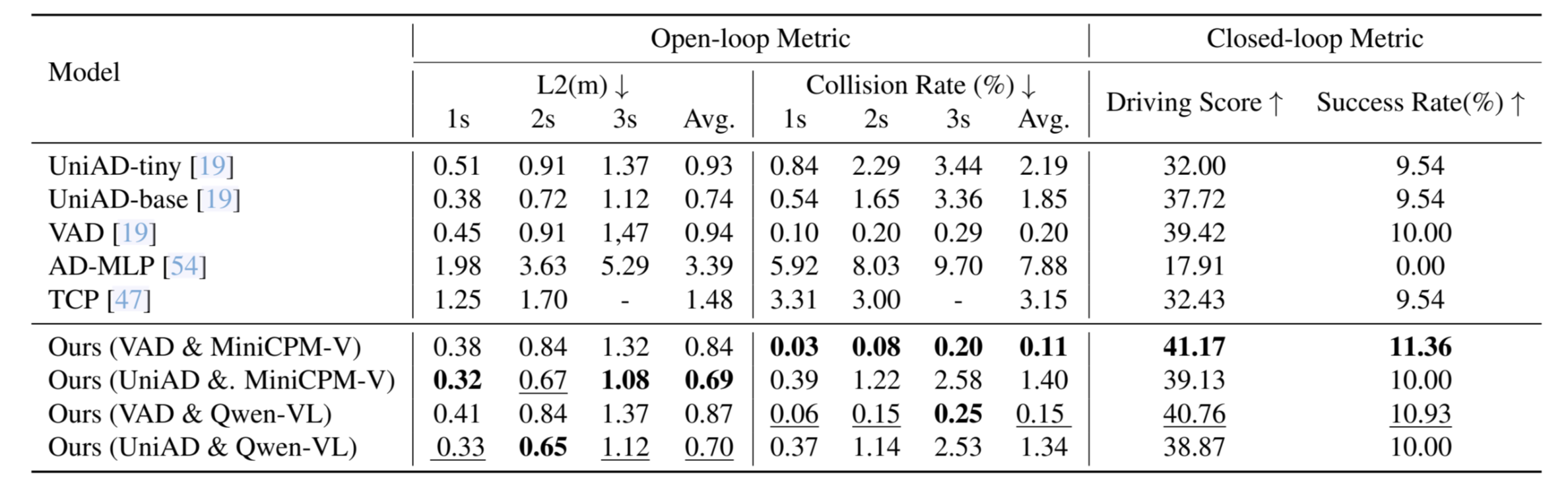
End-to-end autonomous driving has emerged as a promising approach to unify perception, prediction, and planning within a single framework, reducing information loss and improving adaptability. However, existing methods often rely on fixed and sparse trajectory supervision, limiting their ability to capture the hierarchical reasoning process that human drivers naturally employ. To bridge this gap, we propose ReAL-AD, a Reasoning-Augmented Learning framework that structures decision-making in autonomous driving based on the three-tier human cognitive model: Driving Strategy, Driving Decision, and Driving Operation, where Vision-Language Models (VLMs) are incorporated to enhance situational awareness and structured reasoning across these levels. Specifically, we introduce: (1) the Strategic Reasoning Injector, which formulates high-level driving strategies by interpreting complex traffic contexts from VLM-generated insights; (2) the Tactical Reasoning Integrator, which refines strategic intent into interpretable tactical choices such as lane changes, overtaking, and speed adjustments; and (3) the Hierarchical Trajectory Decoder, which progressively translates tactical decisions into precise control actions for smooth and human-like trajectory execution. Extensive evaluations show that integrating our framework improves planning accuracy and safety by over 30%, making end-to-end autonomous driving more interpretable and aligned with human-like hierarchical reasoning.