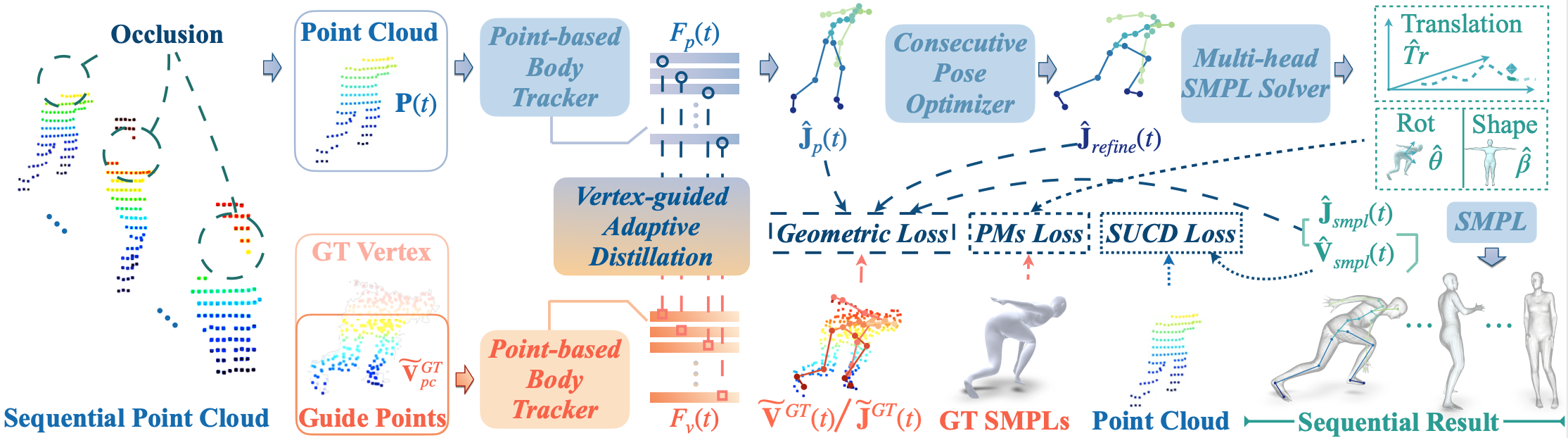
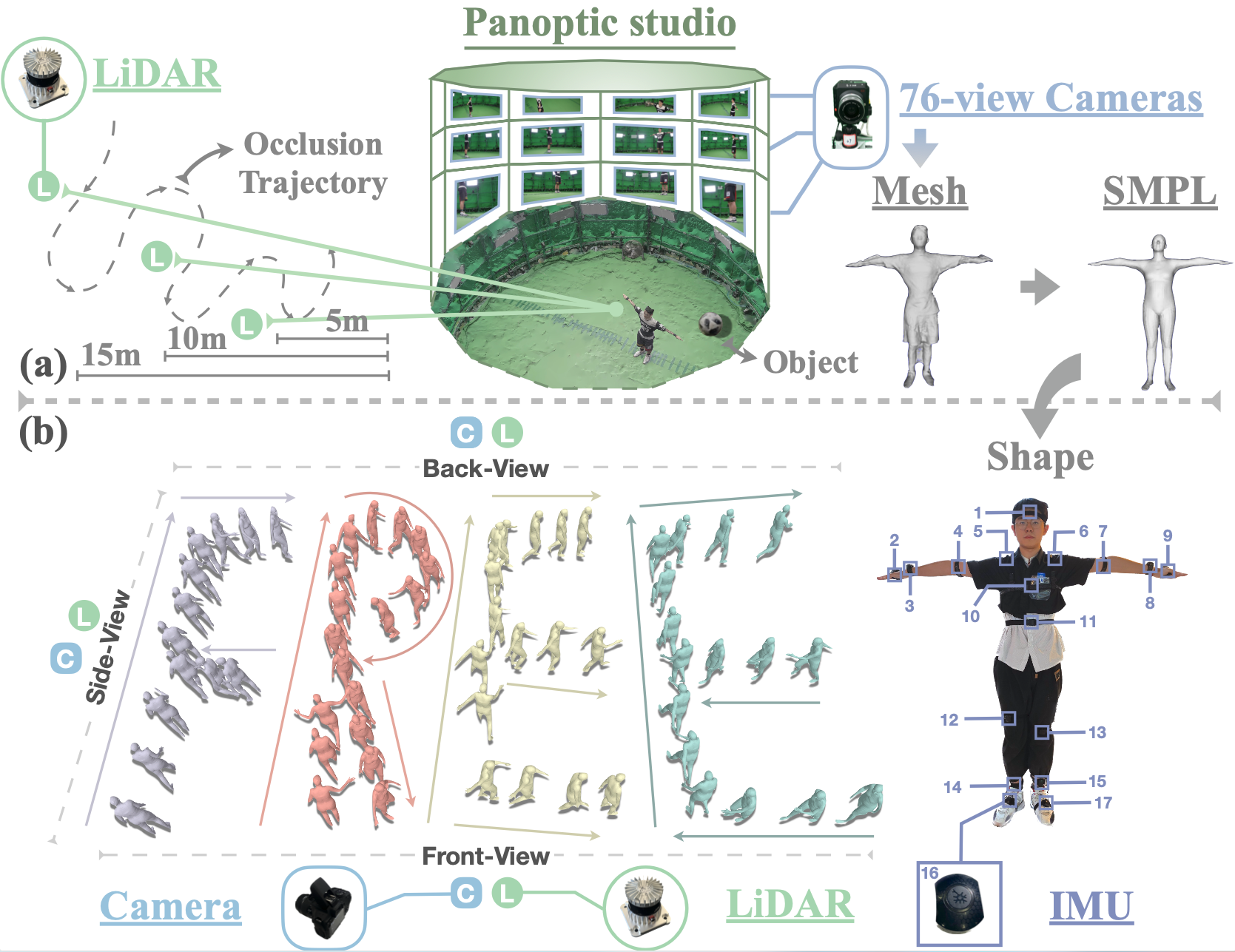
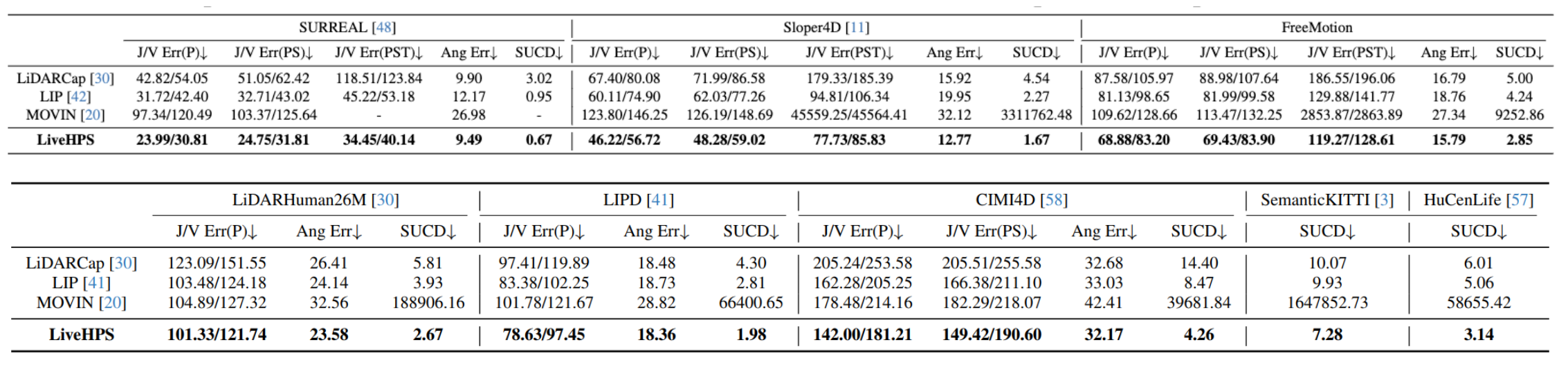
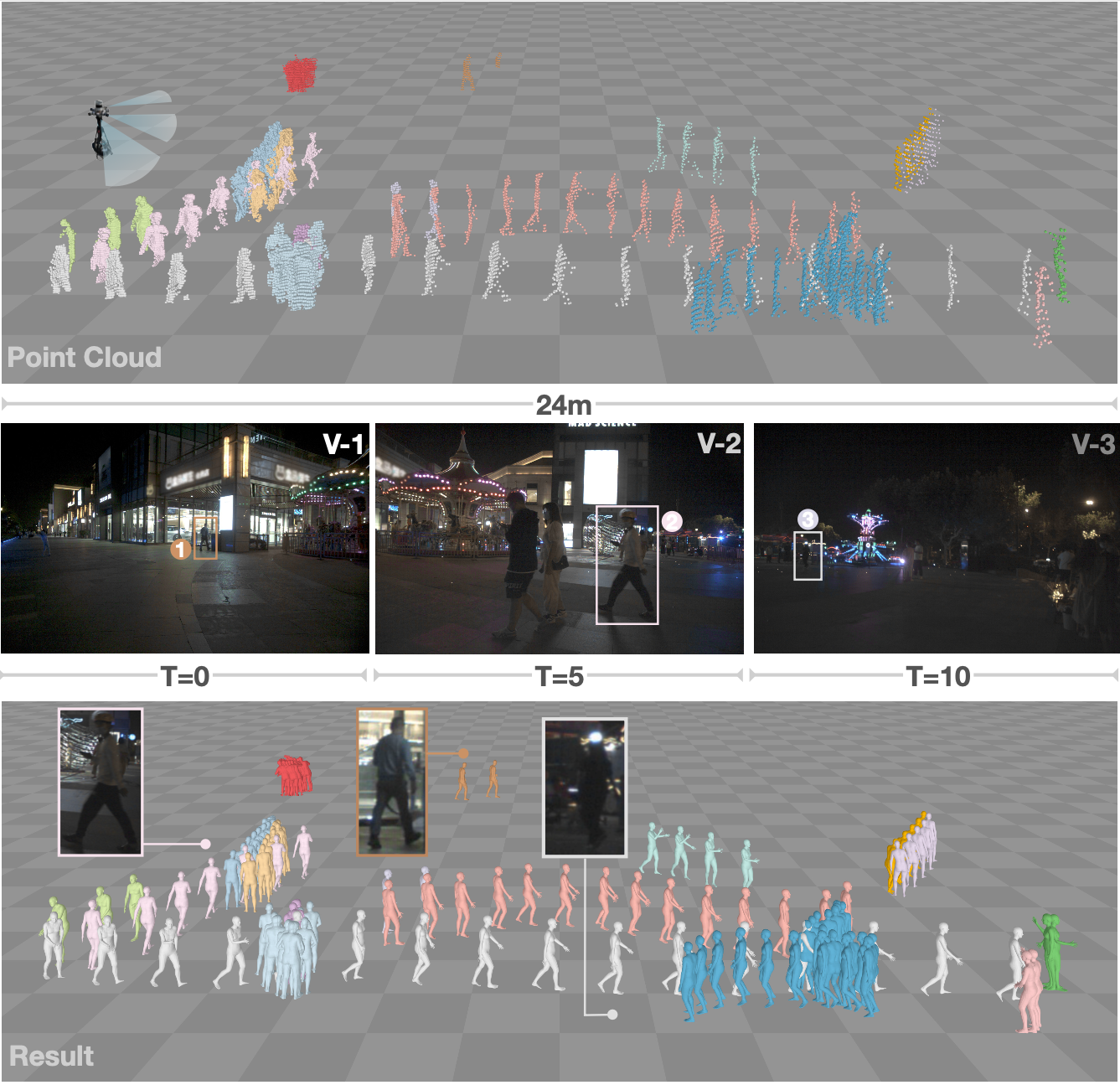
For human-centric large-scale scenes, fine-grained modeling for 3D human global pose and shape is significant for scene understanding and can benefit many real-world applications. In this paper, we present LiveHPS, a novel single-LiDAR-based approach for scene-level Human Pose and Shape estimation without any limitation of light conditions and wearable devices. In particular, we design a distillation mechanism to mitigate the distribution-varying effect of LiDAR point clouds and exploit the temporal-spatial geometric and dynamic information existing in consecutive frames to solve the occlusion and noise disturbance. LiveHPS, with its efficient configuration and high-quality output, is well-suited for real-world applications. Moreover, we propose a huge human motion dataset, named FreeMotion, which is collected in various scenarios with diverse human poses, shapes and translations. It consists of multi-modal and multi-view acquisition data from calibrated and synchronized LiDARs, cameras, and IMUs. Extensive experiments on our new dataset and other public datasets demonstrate the SOTA performance and robustness of our approach.
 Figure 1. We propose a novel single-LiDAR-based approach for 3D HPS in large-scale scenarios, which is not limited to fixed studios, light conditions, and wearable devices. Our method predicts full human SMPL parameters(pose, shape, translation) from consecutive LiDAR point clouds and performs well for challenging poses and occlusion situations.
Figure 1. We propose a novel single-LiDAR-based approach for 3D HPS in large-scale scenarios, which is not limited to fixed studios, light conditions, and wearable devices. Our method predicts full human SMPL parameters(pose, shape, translation) from consecutive LiDAR point clouds and performs well for challenging poses and occlusion situations.