Human motion prediction is crucial for human-centric multimedia understanding and interacting. Current methods typically rely on ground truth human poses as observed input, which is not practical for real-world scenarios where only raw visual sensor data is available. To implement these methods in practice, a pre-phrase of pose estimation is essential. However, such two-stage approaches often lead to performance degradation due to the accumulation of errors.
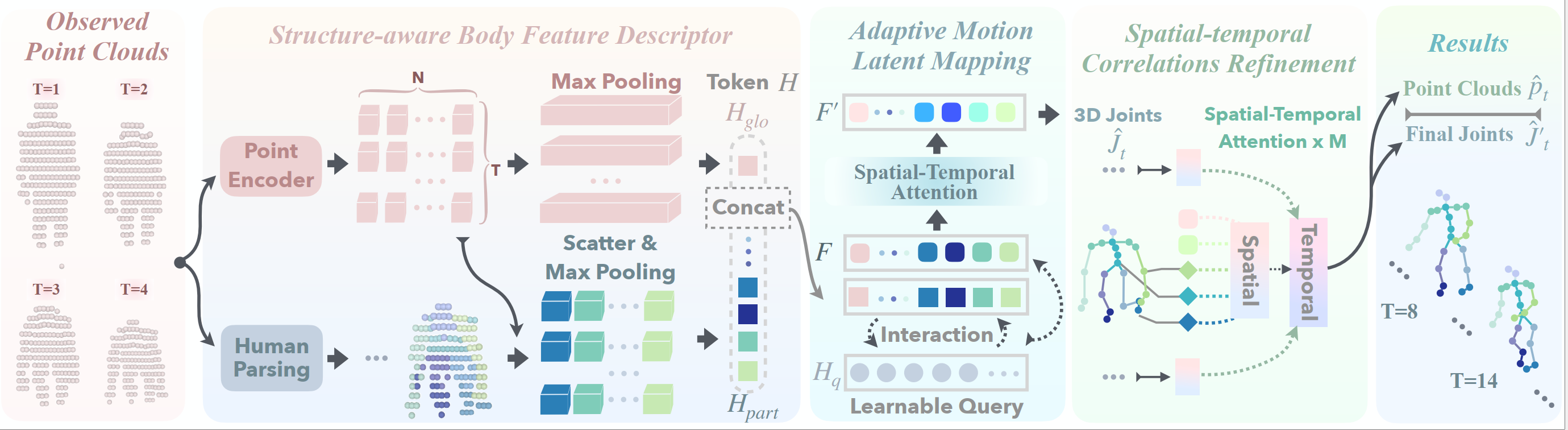
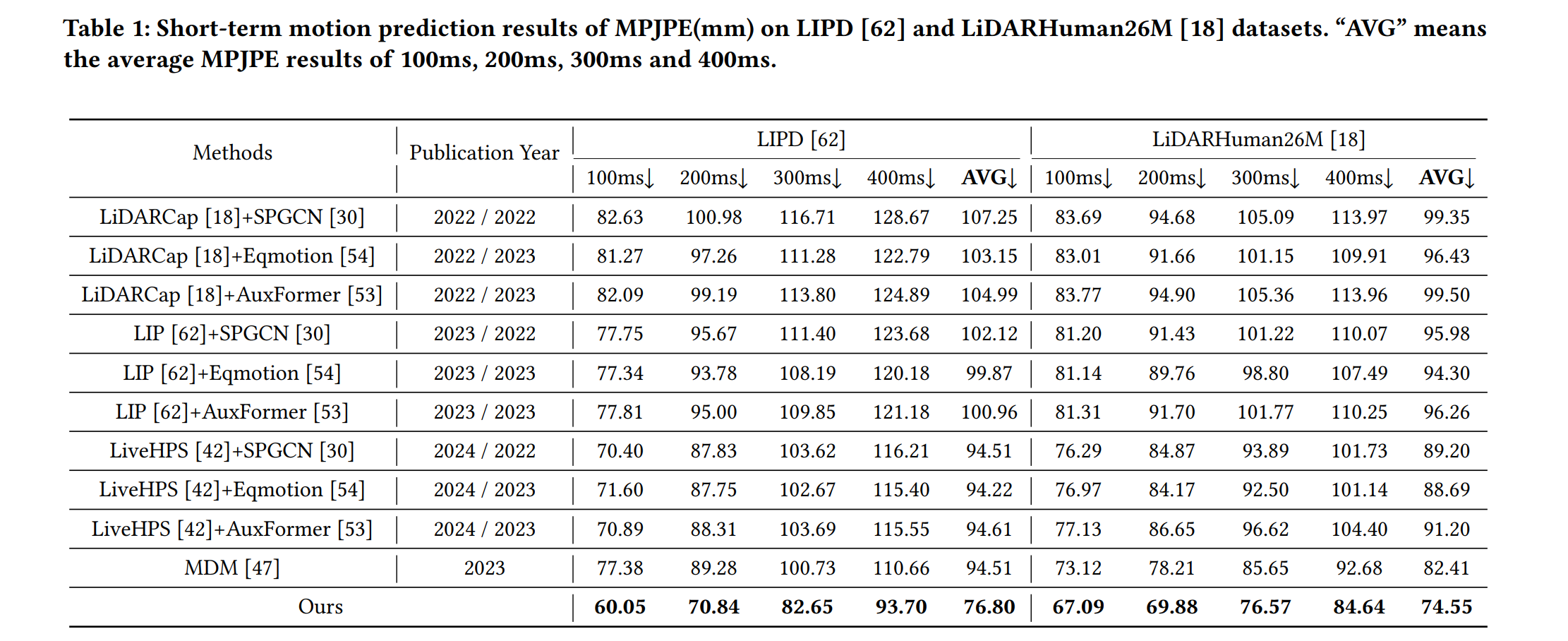
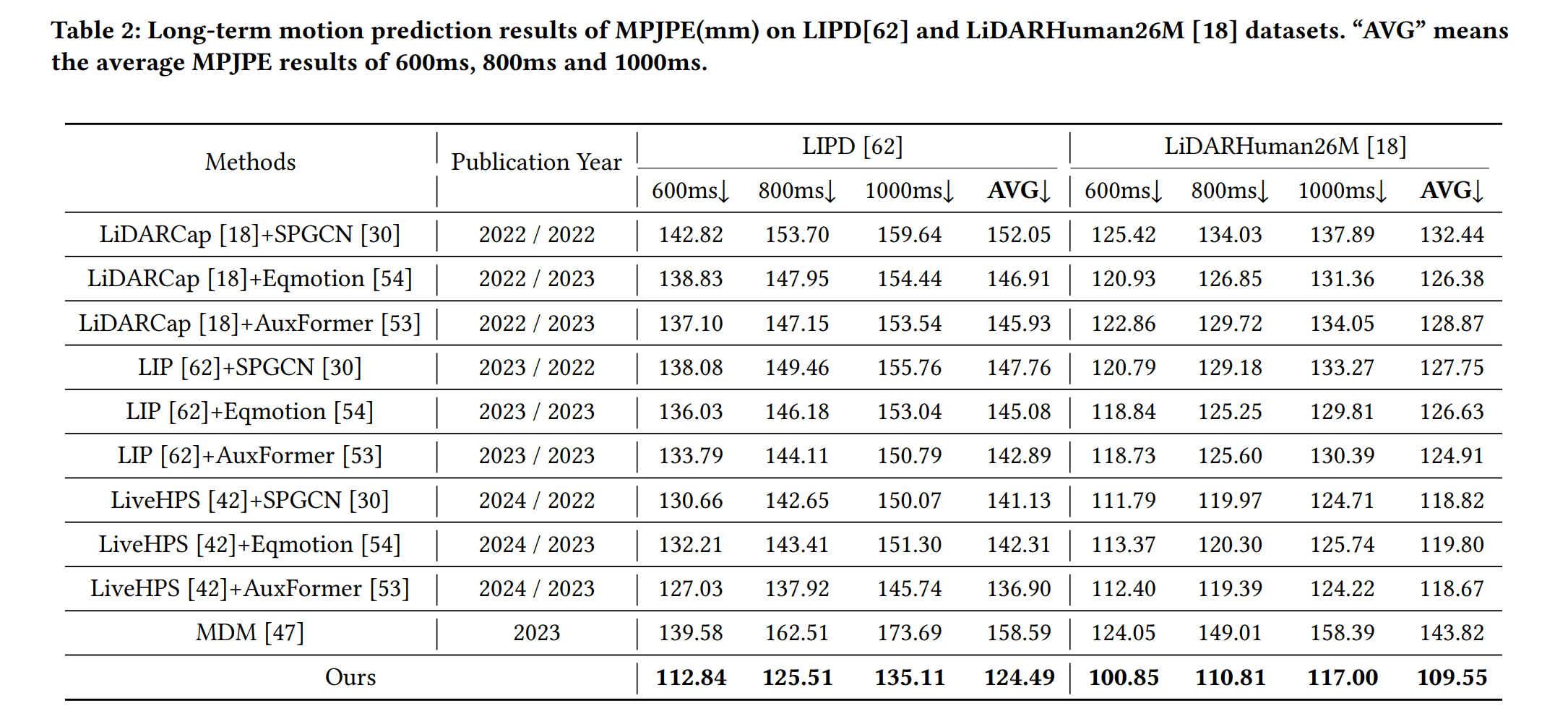
Moreover, reducing raw visual data to sparse keypoint representations significantly diminishes the density of information, resulting in the loss of fine-grained features. In this paper, we propose LiDAR-HMP, the first single-LiDAR-based 3D human motion prediction approach, which receives the raw LiDAR point cloud as input and forecasts future 3D human poses directly. Building upon our novel structure-aware body feature descriptor, LiDAR-HMP adaptively maps the observed motion manifold to future poses and effectively models the spatial-temporal correlations of human motions for further refinement of prediction results. Extensive experiments show that our method achieves state-of-the-art performance on two public benchmarks and demonstrates remarkable robustness and efficacy in real-world deployments.
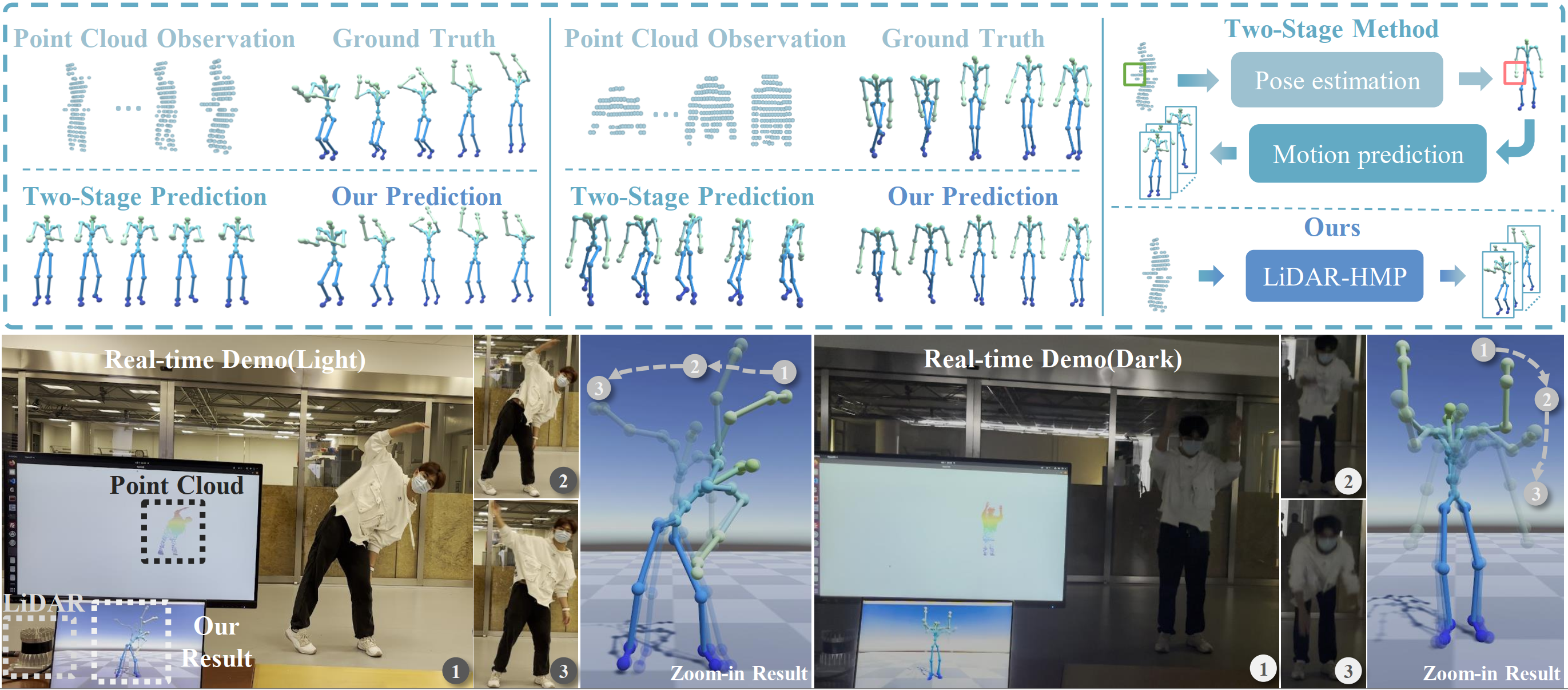 Visualization of our motion prediction performance. The top figure demonstrates the comparison of our LiDAR-HMP and two-stage method on LIPD test set. The bottom figure highlights LiDAR-HMP's practicality in real-world deployment, unfettered by lighting conditions, where markers 1, 2, and 3 indicate the current moment and predicted poses for the future 0.4s and 1.0s, respectively. With online captured LiDAR point cloud, our method achieves real-time promising prediction results, which is significant for real-world applications.
Visualization of our motion prediction performance. The top figure demonstrates the comparison of our LiDAR-HMP and two-stage method on LIPD test set. The bottom figure highlights LiDAR-HMP's practicality in real-world deployment, unfettered by lighting conditions, where markers 1, 2, and 3 indicate the current moment and predicted poses for the future 0.4s and 1.0s, respectively. With online captured LiDAR point cloud, our method achieves real-time promising prediction results, which is significant for real-world applications.