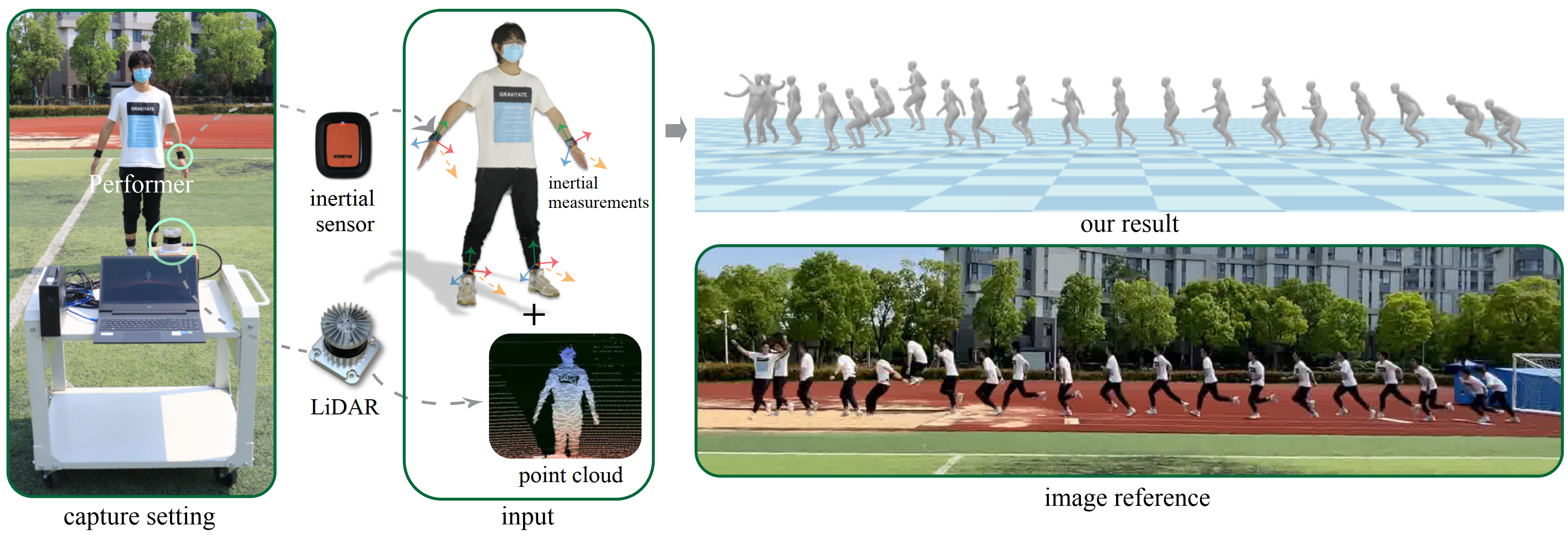
 Figure 1. We propose a multi-modal motion capture approach, LIP, that estimates challenging human motions with accurate local pose and global translation in large-scale scenarios using single LiDAR and four inertial measurement units.
Figure 1. We propose a multi-modal motion capture approach, LIP, that estimates challenging human motions with accurate local pose and global translation in large-scale scenarios using single LiDAR and four inertial measurement units.
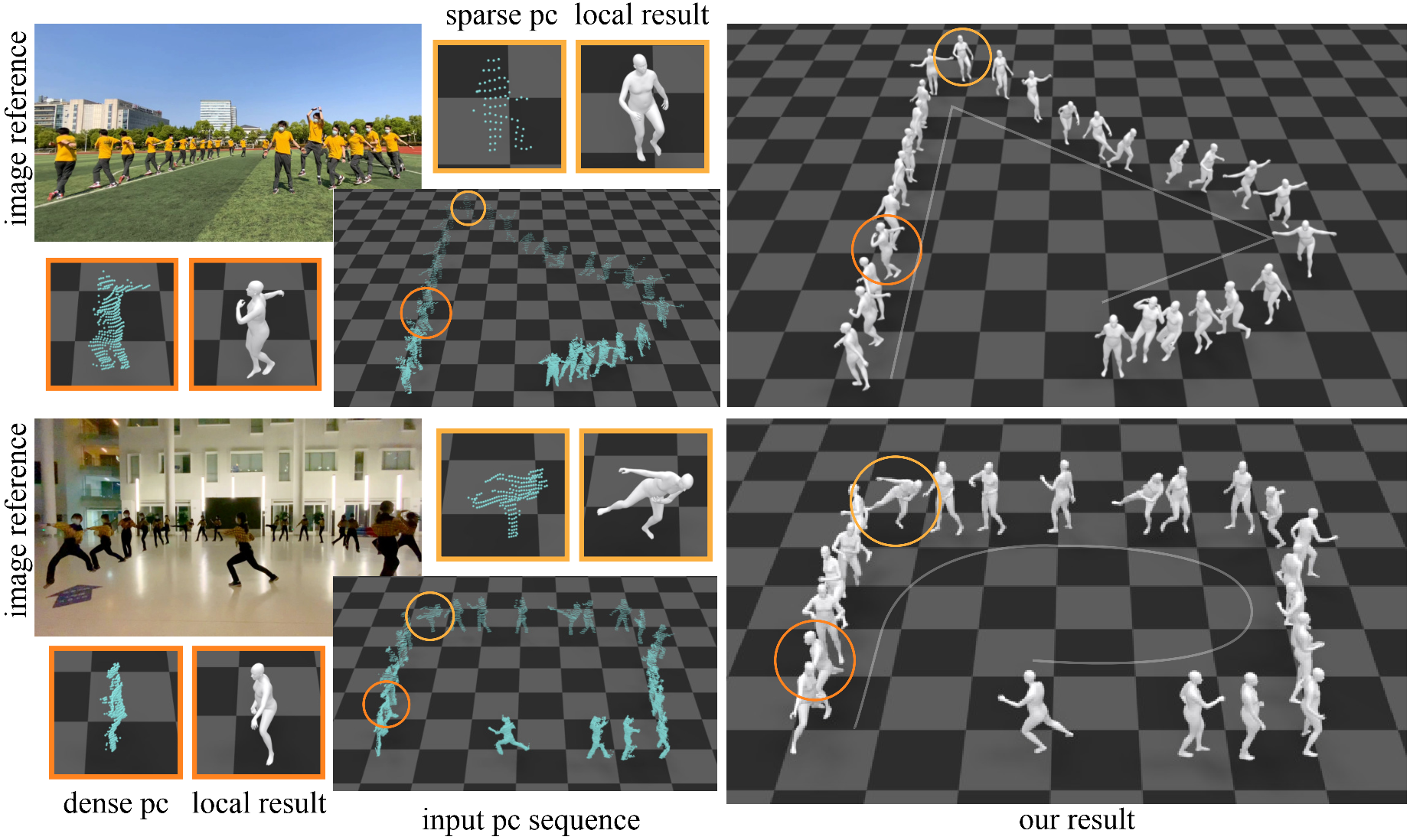
We propose a multi-sensor fusion method for capturing challenging 3D human motions with accurate consecutive local poses and global trajectories in large-scale scenarios, only using single LiDAR and 4 IMUs, which are set up conveniently and worn lightly. Specifically, to fully utilize the global geometry information captured by LiDAR and local dynamic motions captured by IMUs, we design a two-stage pose estimator in a coarse-to-fine manner, where point clouds provide the coarse body shape and IMU measurements optimize the local actions. Furthermore, considering the translation deviation caused by the view-dependent partial point cloud, we propose a pose-guided translation corrector. It predicts the offset between captured points and the real root locations, which makes the consecutive movements and trajectories more precise and natural. Moreover, we collect a LiDAR-IMU multi-modal mocap dataset, LIPD, with diverse human actions in long-range scenarios. Extensive quantitative and qualitative experiments on LIPD and other open datasets all demonstrate the capability of our approach for compelling motion capture in large-scale scenarios, which outperforms other methods by an obvious margin. We will release our code and captured dataset to stimulate future research.
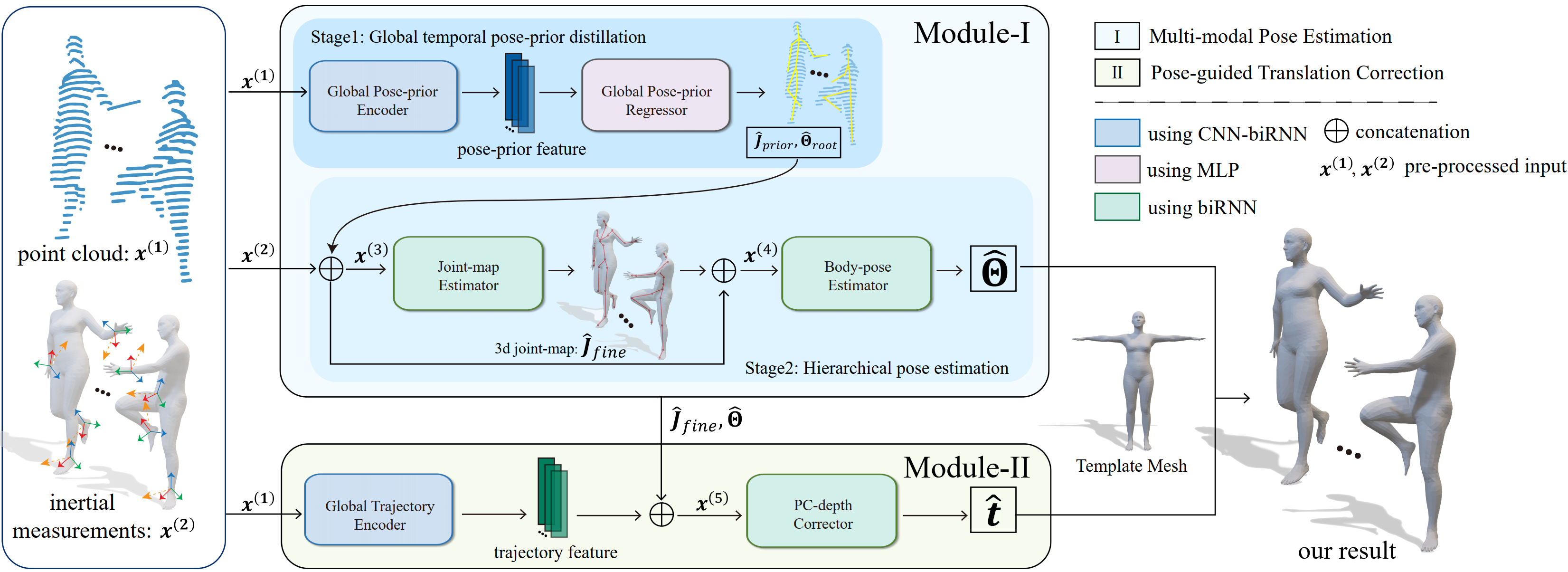
Overview of our pipeline. It consists of two cooperative modules: `Multi-modal Pose Estimation` (Module-I) and `Pose-guided Translation Correction` (Module-II) to estimate skeletal pose and global translation from sparse IMU and LiDAR inputs.
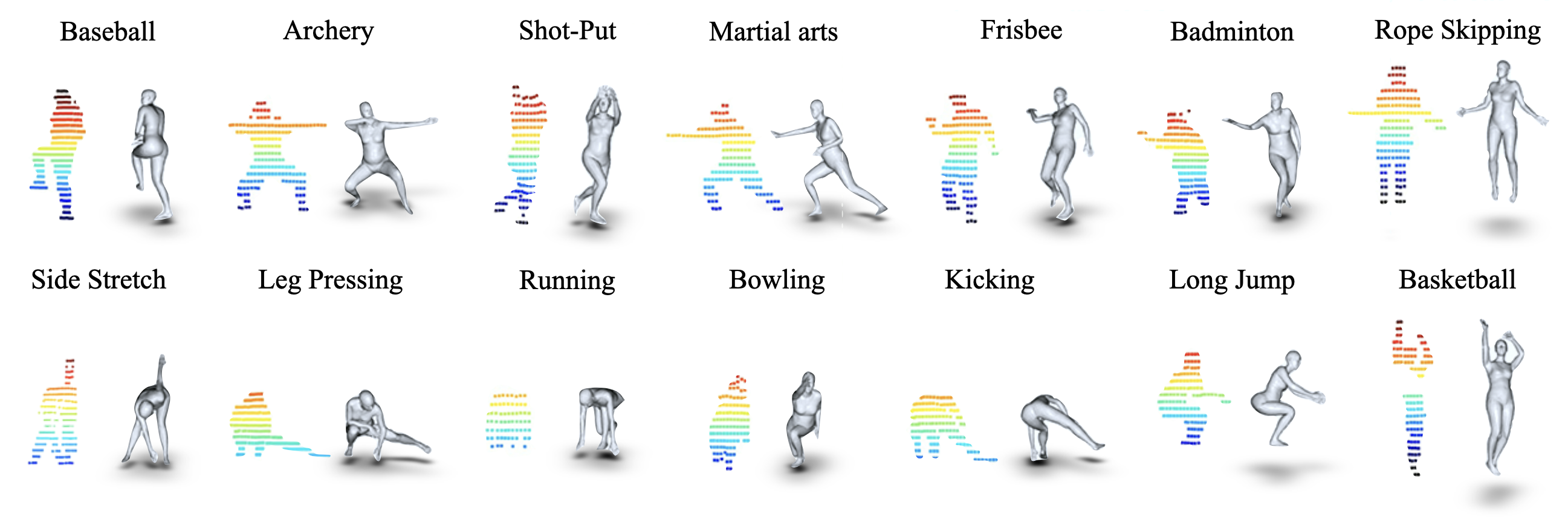
LIPD dataset contains diverse human poses from daily actions to professional sports actions. We demonstrate the point cloud and corresponding ground-truth mesh for several action samples. Such complex poses, like crouching or having the back to LiDAR in the second row, bring challenges for accurate mocap due to severe self-occlusions. We also have multi-person scenarios with external occlusions, as the last basketball case shows, where the player's body is partially covered by others in the LiDAR's view.
LIPD |── PC_Data (LiDAR) | |── realdata (LIPD record data) | | |── 921 (record date) | | | |── seq1 (sequence) | | | | |── 0.bin | | | | |── 1.bin | | | | |── ... | |── test (synthetic test data) | | |── DIP | | | |── s_01 | | | | |── 01 | | | | | |── 0.bin | | | | | |── 1.bin | | | | | |── ... | |── train (synthetic test data) | | |── CMU | | | |── 01 | | | | |── 01_01_stageii | | | | | |── 0.bin | | | | | |── 1.bin | | | | | |── ... |── LIPD_train.pkl (Preprocessed data in pkl) | |── info (Dict that stores one frame of information) | | |── pc (point cloud path) | | |── gt_r (ground-truth of global rotation in 6D) | | |── gt_joint (ground-truth of 3D human joint positions) | | |── imu_ori (IMU rotation data) | | |── imu_acc (IMU accelerate data) | | |── gt (ground-truth of SMPL pose parameters) | | |── seq_path (sequence path to which the frame belongs) |── LIPD_test.pkl |── CMU.pkl |── TC_test.pkl |── ...
np.fromfile(file_path, dtype=np.float32).reshape(-1, 3) to load the file. Columns 0-3 represent x, y, z respectively.
@ARTICLE{10049734,
author={Ren, Yiming and Zhao, Chengfeng and He, Yannan and Cong, Peishan and Liang, Han and Yu, Jingyi and Xu, Lan and Ma, Yuexin},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={LiDAR-aid Inertial Poser: Large-scale Human Motion Capture by Sparse Inertial and LiDAR Sensors},
year={2023},
volume={29},
number={5},
pages={2337-2347},
doi={10.1109/TVCG.2023.3247088}}